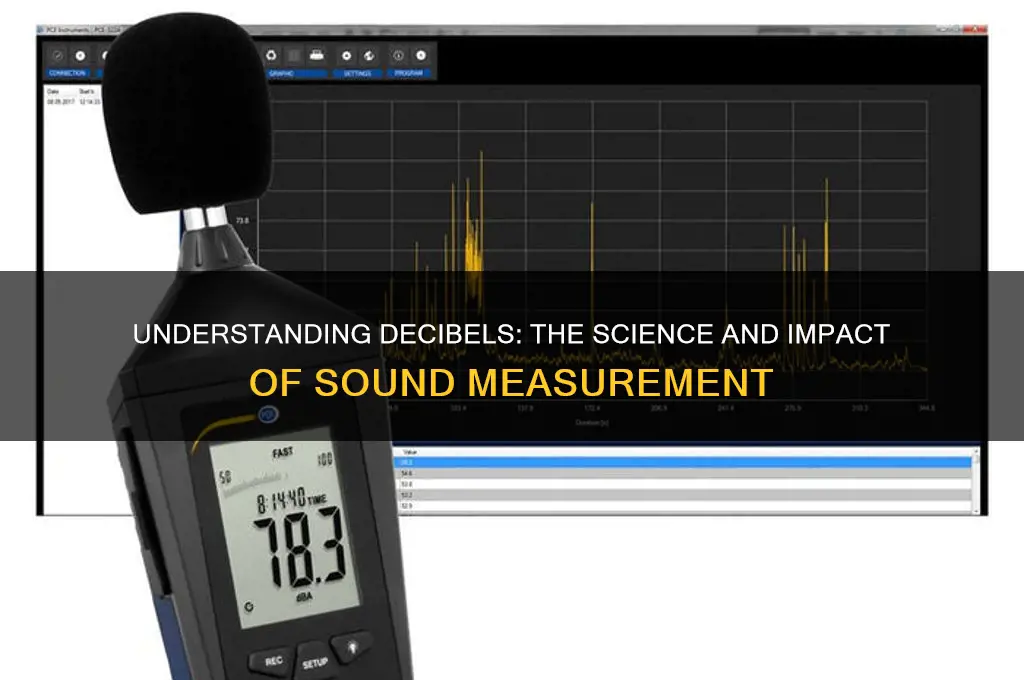
Decibels (dB) are a fundamental unit of measurement used to quantify the intensity or power of sound. Unlike linear units, decibels operate on a logarithmic scale, making them particularly useful for representing the vast range of sound levels that the human ear can detect, from the faintest whisper to the loudest thunder. Understanding dB is crucial in fields such as acoustics, audio engineering, and environmental science, as it helps in assessing sound quality, ensuring compliance with noise regulations, and protecting hearing health. By measuring sound in decibels, we can effectively communicate and manage the impact of noise in various settings, from concert halls to industrial workplaces.
| Characteristics | Values |
|---|---|
| Definition | Decibels (dB) are a logarithmic unit used to measure sound intensity or pressure relative to a reference level. |
| Reference Level | For sound in air, the reference level is typically 20 micropascals (µPa), which is the threshold of human hearing. |
| Formula | ( L_p = 20 \log_{10} \left( \frac \right) ), where ( L_p ) is the sound pressure level in dB, ( p ) is the measured sound pressure, and ( p_0 ) is the reference pressure. |
| Logarithmic Scale | Each 10 dB increase represents a tenfold increase in sound intensity; each 3 dB increase represents a doubling of sound pressure. |
| Threshold of Hearing | 0 dB (softest sound audible to the average human ear). |
| Normal Conversation | 40–60 dB. |
| City Traffic | 70–90 dB. |
| Loud Music (Rock Concert) | 100–120 dB. |
| Pain Threshold | 130 dB and above. |
| Maximum Safe Exposure (Without Hearing Protection) | 85 dB for 8 hours; exposure times decrease as sound levels increase (e.g., 100 dB for 15 minutes). |
| Applications | Used in acoustics, audio engineering, environmental noise monitoring, and hearing conservation. |
| Weighting Scales | A-weighting (dBA) to approximate human ear sensitivity; C-weighting (dBC) for peak sound levels; Z-weighting (dBG) for flat frequency response. |
| Measurement Tools | Sound level meters, decibel meters, and smartphone apps with decibel measurement capabilities. |
Explore related products






What You'll Learn
- Database Basics: Understanding how sound databases (DBs) store and organize audio data efficiently
- Sound File Formats: Exploring common formats like WAV, MP3, and FLAC in sound DBs
- Metadata in Sound DBs: Role of tags, timestamps, and descriptors in organizing audio files
- Sound DB Applications: Uses in music libraries, voice recognition, and sound effect archives
- Sound DB Management: Tools and techniques for indexing, searching, and retrieving audio data
![]()
Database Basics: Understanding how sound databases (DBs) store and organize audio data efficiently
Sound databases (DBs) are specialized systems designed to store, organize, and retrieve audio data efficiently. Unlike general databases that handle text or numbers, sound DBs must manage large, continuous data streams while preserving quality and accessibility. At their core, these databases rely on structured metadata—tags like artist, genre, duration, and keywords—to index audio files. This metadata enables quick searches and filtering, ensuring users can locate specific sounds without sifting through raw data. For instance, a sound effect library might tag a file as "thunder_crack_5sec_stereo," allowing users to find it instantly by searching for "thunder" or "stereo."
Efficient storage is another critical aspect of sound DBs. Audio files are often compressed using formats like MP3, FLAC, or WAV to reduce size without sacrificing quality. Advanced DBs may employ lossless compression for archival purposes or lossy compression for streaming applications. Additionally, sound DBs frequently use hierarchical storage systems, keeping frequently accessed files on fast SSDs and archiving less-used data on cost-effective cloud or tape storage. This tiered approach balances speed and cost, ensuring optimal performance for diverse use cases, from music production to voice recognition systems.
Organization in sound DBs goes beyond metadata and storage. These systems often incorporate acoustic features extracted from audio files, such as frequency spectra, tempo, or pitch. Machine learning algorithms analyze these features to categorize sounds automatically, enabling semantic searches like "find all high-pitched bird calls." This level of organization is particularly valuable in large-scale applications, such as wildlife monitoring or audio forensics, where manual tagging is impractical. For example, a database of urban soundscapes might cluster recordings by noise type—traffic, construction, or conversation—facilitating research on environmental acoustics.
Despite their sophistication, sound DBs face challenges like data redundancy and scalability. To mitigate redundancy, deduplication techniques identify and remove identical or near-identical audio clips, freeing up storage space. Scalability is addressed through distributed architectures, where data is split across multiple servers to handle growing collections and user demands. For instance, a global music streaming service might partition its database by region, ensuring users in Asia access servers closer to them for faster playback. These strategies highlight the balance sound DBs must strike between accessibility, efficiency, and resource management.
In practice, designing a sound DB requires careful consideration of the intended use case. A database for medical speech analysis, for example, would prioritize high-fidelity recordings and detailed metadata like patient age or diagnosis. In contrast, a gaming sound library might focus on quick retrieval and categorization by emotion or action. Practical tips include using standardized metadata schemas like the International Association of Sound and Audiovisual Archives (IASA) guidelines and regularly updating acoustic feature extraction models to improve accuracy. By tailoring the database to its purpose, developers can create a powerful tool that transforms raw audio into actionable insights.
Unveiling the Science: How Organs Produce Musical Sounds
You may want to see also
Explore related products






![]()
Sound File Formats: Exploring common formats like WAV, MP3, and FLAC in sound DBs
Sound databases (DBs) are repositories of audio files, each encoded in specific formats that balance quality, size, and usability. Among the most prevalent are WAV, MP3, and FLAC, each serving distinct purposes in sound storage and distribution. WAV files, developed by Microsoft and IBM, are uncompressed and lossless, preserving audio quality at the cost of large file sizes. This makes them ideal for professional audio editing and archiving, where fidelity is paramount. However, their bulkiness limits practicality for streaming or casual listening.
In contrast, MP3 files revolutionized digital audio by using lossy compression to drastically reduce file size, making them a staple for portable music players and online sharing. While this compression sacrifices some audio detail—particularly in high frequencies or complex passages—the trade-off is often imperceptible to the average listener. MP3’s efficiency has cemented its role in sound DBs designed for accessibility and widespread distribution. Yet, audiophiles and professionals often criticize its limitations, especially when compared to formats like FLAC.
FLAC (Free Lossless Audio Codec) bridges the gap between WAV’s bulk and MP3’s compromises by offering lossless compression. It reduces file size without discarding any audio data, ensuring pristine quality while remaining more manageable than WAV. This format is increasingly popular in sound DBs catering to high-fidelity enthusiasts and archival purposes. However, its larger size compared to MP3 can still pose challenges for storage and streaming, particularly in resource-constrained environments.
Choosing the right format for a sound DB depends on its intended use. For archival or professional applications, WAV or FLAC ensures uncompromised quality. For consumer-facing platforms prioritizing accessibility, MP3 remains a practical choice. Emerging formats like AAC or Opus offer further optimizations, but WAV, MP3, and FLAC remain foundational due to their widespread support and clear use cases. Understanding these formats empowers creators and curators to tailor their sound DBs effectively, balancing technical constraints with user needs.
Nascence: Does This Steam Game Have Sound?
You may want to see also
Explore related products






![]()
Metadata in Sound DBs: Role of tags, timestamps, and descriptors in organizing audio files
Sound databases (DBs) are repositories designed to store, manage, and retrieve audio files efficiently. At their core, these systems rely on metadata—structured information that describes the content, context, and characteristics of audio recordings. Among the most critical metadata elements are tags, timestamps, and descriptors, which collectively form the backbone of organization within sound DBs. Without these, audio files would be nearly impossible to search, categorize, or analyze at scale.
Consider tags as the categorical labels that classify audio files based on attributes like genre, artist, mood, or instrument. For instance, a field recording of a rainforest might be tagged with "nature," "ambient," and "wildlife." Tags act as filters, enabling users to narrow down vast collections quickly. However, their effectiveness hinges on consistency and standardization. A poorly defined tagging system—where "jazz" and "Jazz" are treated as distinct categories—can lead to fragmentation. To avoid this, sound DB administrators should adopt controlled vocabularies or taxonomies, ensuring uniformity across entries.
Timestamps, on the other hand, provide temporal context, pinpointing when an audio event occurs within a recording or when the file was created. In sound DBs, timestamps are invaluable for time-series analysis, such as tracking bird calls at dawn or mapping noise pollution over a cityscape. For example, a timestamped database of urban sounds could reveal hourly patterns in traffic noise, aiding urban planners in noise mitigation strategies. Precision is key here—timestamps should be recorded in standardized formats (e.g., ISO 8601) and synchronized with accurate clocks to maintain reliability.
Descriptors bridge the gap between objective data and subjective interpretation by providing detailed textual or numerical annotations. These can include technical specifications (e.g., sample rate, bit depth) or qualitative observations (e.g., "high-pitched whistle at 0:45"). Descriptors are particularly useful in research-oriented sound DBs, where users might search for specific acoustic phenomena. For instance, a musicologist could query for "Baroque flute solos with trills" if descriptors include both instrumentation and performance techniques. However, creating descriptors is labor-intensive and requires domain expertise, making it a trade-off between depth of information and scalability.
In practice, the interplay of tags, timestamps, and descriptors transforms sound DBs from static archives into dynamic tools for exploration and analysis. For example, a wildlife sound DB could use tags to categorize bird species, timestamps to track migration patterns, and descriptors to note call variations. Together, these metadata elements enable researchers to ask complex questions—such as "How has the frequency of nocturnal bird calls changed over the past decade?"—and extract actionable insights from the data.
To maximize the utility of metadata in sound DBs, administrators should prioritize interoperability and user-friendliness. This includes adopting open standards (e.g., EBU Core for broadcast media), providing intuitive search interfaces, and offering bulk editing tools for metadata maintenance. By doing so, sound DBs can serve not just as storage solutions, but as platforms for discovery, creativity, and knowledge generation in fields ranging from ecology to musicology.
Understanding the Science Behind Producing Ultrasonic Sound Waves
You may want to see also
Explore related products






![]()
Sound DB Applications: Uses in music libraries, voice recognition, and sound effect archives
Sound databases (DBs) are the unsung heroes of modern audio management, serving as structured repositories that organize, store, and retrieve sound files efficiently. In music libraries, these DBs are revolutionizing how artists, producers, and enthusiasts access and utilize audio resources. For instance, platforms like Spotify and Apple Music rely on sound DBs to categorize tracks by genre, artist, tempo, and mood, enabling users to discover music tailored to their preferences. These systems often use metadata tagging, allowing for granular searches—imagine finding every 120 BPM track with a minor key in seconds. This level of organization not only enhances user experience but also empowers creators to analyze trends and refine their work.
Voice recognition systems, another critical application of sound DBs, depend on vast datasets of spoken language to improve accuracy. Companies like Google and Amazon train their algorithms using DBs containing millions of voice samples across accents, languages, and age groups. For example, a DB might include recordings of children aged 5–12 to enhance recognition of younger voices. However, building such DBs requires careful curation to avoid biases—a dataset lacking diverse representation can lead to misrecognition. Practical tip: When contributing to open-source voice DBs, ensure recordings are clear, varied, and include phrases from everyday conversation to maximize utility.
Sound effect archives, often used in film, gaming, and multimedia, leverage DBs to streamline workflows for sound designers. Libraries like BBC Sound Effects and SoundSnap categorize effects by environment, action, and intensity, making it easy to find the perfect "creaking door" or "thunderstorm." These DBs often include technical metadata like frequency range and file format, ensuring compatibility with editing software. For instance, a sound designer working on a horror game might filter for high-frequency, distorted sounds to create tension. Caution: Over-reliance on popular DBs can lead to repetitive audio in media—balance by recording original sounds or blending multiple effects for uniqueness.
Comparing these applications reveals a common thread: sound DBs thrive on structure and specificity. Music libraries prioritize metadata for creative exploration, voice recognition DBs demand diversity for accuracy, and sound effect archives focus on technical details for seamless integration. Each use case highlights the importance of tailoring DB design to its purpose. For those building their own sound DBs, start by defining clear objectives—whether it’s curating a niche music collection or compiling regional dialects for a voice assistant. The takeaway? A well-designed sound DB isn’t just a storage tool; it’s a dynamic resource that amplifies creativity and functionality across industries.
Is Ministry of Sound Safe? A Comprehensive Safety Review and Guide
You may want to see also
Explore related products




![]()
Sound DB Management: Tools and techniques for indexing, searching, and retrieving audio data
Effective sound database (DB) management hinges on precise indexing, efficient searching, and seamless retrieval of audio data. At its core, indexing involves tagging audio files with metadata—such as timestamps, speaker identities, or emotional tones—to create a searchable framework. Tools like Sonic Visualiser and Audacity allow users to annotate waveforms with labels, while advanced systems like Google’s AudioSet use machine learning to auto-tag sounds with categories like "dog barking" or "rainfall." Without robust indexing, even the most extensive audio libraries become unwieldy, rendering retrieval a time-consuming guessing game.
Searching audio databases demands specialized techniques, as traditional text-based queries fall short. Content-based audio retrieval (CBIR) systems analyze acoustic features—frequency, tempo, or spectral patterns—to match queries with similar sounds. For instance, Shazam identifies songs by comparing a short sample to its vast database using fingerprinting algorithms. Similarly, Spotify’s audio search leverages mel-frequency cepstral coefficients (MFCCs) to find tracks with similar rhythms or instruments. However, balancing precision and recall remains a challenge; overly specific queries may miss relevant results, while broad searches yield noise.
Retrieval efficiency is critical, especially in large-scale applications like broadcasting or forensic analysis. Distributed database systems, such as Apache Cassandra, store audio data across multiple nodes, enabling parallel searches and reducing latency. Compression techniques like MP3 or Opus minimize storage costs without sacrificing quality, though lossy formats may distort critical audio features. A practical tip: always maintain a lossless backup (e.g., WAV or FLAC) for archival purposes, while using compressed versions for daily operations.
Despite advancements, sound DB management faces unique challenges. Ambiguity in audio data—such as overlapping sounds or background noise—complicates indexing and retrieval. Tools like Librosa offer noise reduction filters, but manual verification remains essential for high-stakes applications. Additionally, privacy concerns arise when managing voice recordings; anonymization techniques, such as voice redaction, can mitigate risks. For instance, Adobe’s Project Awesome Audio uses AI to replace identifiable voices while preserving emotional context.
In conclusion, mastering sound DB management requires a blend of technical tools and strategic techniques. From indexing with metadata to leveraging CBIR and distributed systems, each step plays a vital role in unlocking audio data’s potential. By addressing challenges like ambiguity and privacy, practitioners can build systems that are not only efficient but also ethical and reliable. Whether for creative industries or scientific research, the right approach transforms raw sound into actionable insights.
Fishing in Puget Sound: A Popular Activity for Locals and Tourists
You may want to see also
Frequently asked questions
DBS stands for Decibel Sound Level, a unit used to measure the intensity or loudness of sound.
DBS is measured using a decibel meter or sound level meter, which quantifies sound pressure levels in decibels (dB) relative to a reference point.
A safe DBS level for prolonged listening is generally considered to be 70 dB or below, with exposure to levels above 85 dB potentially causing hearing damage over time.



















