Decoding binary sound involves converting sequences of binary digits (0s and 1s) into audible sound waves, a process that bridges digital data and human perception. Binary sound is typically represented as a series of bits, which can encode audio information through various formats like PCM (Pulse Code Modulation) or other digital audio standards. To decode it, one must first understand the binary data's structure, including its sampling rate, bit depth, and channel configuration. Specialized software or hardware then interprets these bits, reconstructing the original analog waveform by mapping binary values to voltage levels, which are amplified and played through speakers. This process is fundamental in modern audio technology, enabling the playback of digital music, voice recordings, and other sound files stored in binary formats.
| Characteristics | Values |
|---|---|
| Process | Binary sound decoding involves converting a binary sequence (0s and 1s) into an audible sound waveform. |
| Input Format | Binary data (e.g., text file, raw binary, or embedded in other formats). |
| Output Format | Audio waveform (e.g., WAV, MP3, or raw PCM). |
| Decoding Methods | 1. Direct Mapping: Assign binary values to sound frequencies or amplitudes. 2. Modulation Techniques: Use schemes like Amplitude Shift Keying (ASK), Frequency Shift Keying (FSK), or Phase Shift Keying (PSK). 3. Software Tools: Use tools like Audacity, Python libraries (e.g., numpy, scipy), or specialized software for decoding. |
| Sampling Rate | Depends on the target audio quality (e.g., 44.1 kHz for CD quality). |
| Bit Depth | Typically 8-bit or 16-bit for audio representation. |
| Frequency Range | Human audible range: 20 Hz to 20 kHz. |
| Common Challenges | 1. Noise interference. 2. Incorrect binary interpretation. 3. Synchronization issues. |
| Applications | 1. Data recovery from audio files. 2. Steganography (hiding data in audio). 3. Retrocomputing and vintage data storage. |
| Example Tools | 1. Python: numpy, wave, pydub. 2. Audacity: For manual analysis and decoding. 3. Online Tools: Binary to audio converters. |
| Best Practices | 1. Ensure correct binary formatting (e.g., 8-bit chunks for bytes). 2. Use appropriate sampling rates for the target audio. 3. Test with known binary-audio pairs for accuracy. |
Explore related products






What You'll Learn
- Understanding Binary Representation: Learn how sound waves are converted into binary data for digital storage
- Binary to Audio Conversion: Use software tools to decode binary files back into audible sound formats
- Bit Rate and Sampling: Decode binary sound by analyzing bit rate and sampling frequency for accurate reconstruction
- Error Detection in Binary: Identify and correct errors in binary sound data to ensure clear audio output
- Audio File Formats: Decode binary sound by understanding formats like WAV, MP3, and their binary structures
![]()
Understanding Binary Representation: Learn how sound waves are converted into binary data for digital storage
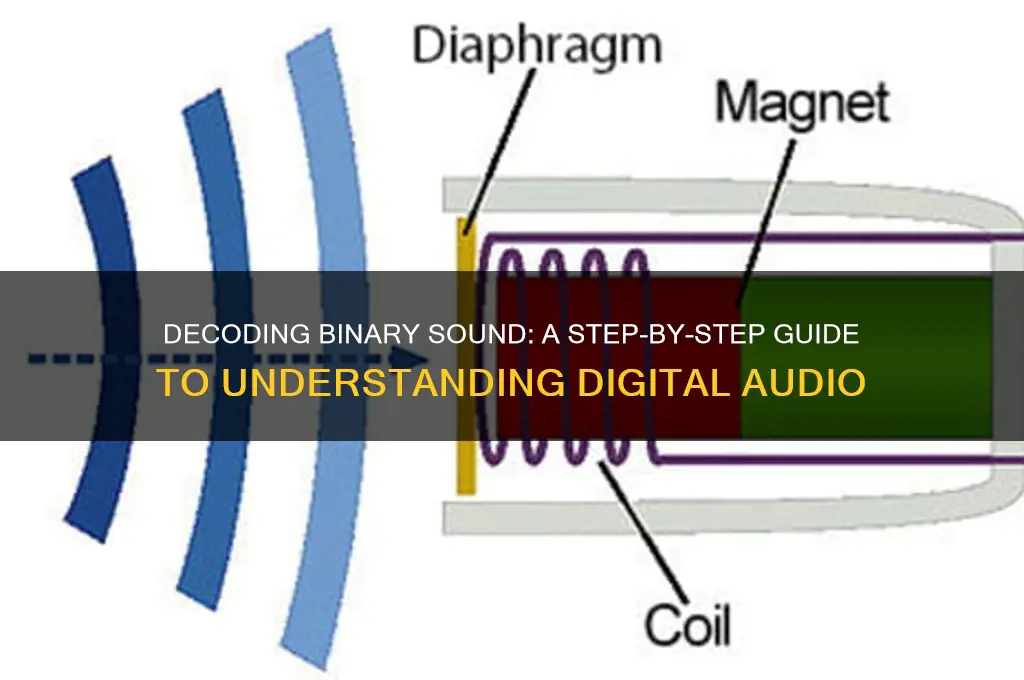
Sound, in its natural form, is an analog wave—a continuous variation of air pressure over time. To store and manipulate sound digitally, it must be converted into a format that computers can understand: binary data. This process involves several steps, each crucial for accurately representing the sound wave in a digital format. The foundation of this conversion lies in understanding binary representation and how it captures the essence of sound waves.
The first step in converting sound waves into binary data is analog-to-digital conversion (ADC). This process begins with a microphone capturing sound waves and converting them into an electrical analog signal. The analog signal is then sampled at regular intervals, measuring the amplitude (loudness) of the wave at each point. The sampling rate, measured in samples per second (Hz), determines how many of these measurements are taken. Common sampling rates include 44.1 kHz (used in CDs) and 48 kHz (used in professional audio). Higher sampling rates capture more detail but require more storage space.
Once the sound wave is sampled, the next step is quantization, where each amplitude measurement is assigned a discrete value. This is necessary because computers process information in discrete steps, not continuous values. The number of possible values depends on the bit depth used. For example, a 16-bit system can represent 65,536 (2^16) amplitude levels, while a 24-bit system offers even greater precision. Quantization introduces a small amount of error, known as quantization noise, but higher bit depths minimize this distortion.
After sampling and quantization, the discrete amplitude values are converted into binary numbers. Each sample is represented as a sequence of 0s and 1s, which computers can store and process. For instance, a 16-bit sample might be represented as `0101001101101001`. This binary data is the digital representation of the original sound wave. The accuracy of this representation depends on the sampling rate and bit depth, with higher values providing a more faithful reproduction of the original sound.
To decode binary sound and convert it back into an audible format, the process is reversed. The binary data is read, and each sequence of 0s and 1s is converted back into discrete amplitude values. These values are then used to reconstruct the analog signal through a digital-to-analog converter (DAC). The reconstructed signal is amplified and sent to a speaker, which vibrates to produce sound waves. This final output is an approximation of the original sound, with the quality depending on the precision of the initial binary representation.
Understanding binary representation is key to grasping how sound waves are converted into digital data. By sampling, quantizing, and encoding the amplitude of sound waves into binary numbers, we can store, manipulate, and reproduce audio with remarkable fidelity. This process underpins all digital audio technologies, from music streaming to voice recording, making it a fundamental concept in modern sound engineering.
Exploring Sound Refraction: Do Beats Play a Role in Acoustic Phenomena?
You may want to see also
Explore related products






![]()
Binary to Audio Conversion: Use software tools to decode binary files back into audible sound formats
Binary to audio conversion is a process that involves transforming binary data, typically stored in files, back into audible sound formats. This is particularly useful for recovering audio from raw binary files, analyzing data streams, or even extracting hidden audio information. To achieve this, various software tools and techniques can be employed, each tailored to different levels of complexity and specific use cases. Below is a detailed guide on how to decode binary files into audible sound using software tools.
One of the most straightforward methods for binary to audio conversion is using specialized software designed for this purpose. Tools like Audacity, a popular open-source audio editor, can be adapted for this task. To decode binary data in Audacity, you first need to ensure the binary file is in a raw format, which contains uncompressed audio data. Open Audacity, go to "File > Import > Raw Data," and select your binary file. You’ll then need to specify the encoding parameters, such as the sample rate, sample format (e.g., 16-bit PCM), and the number of channels (mono or stereo). These parameters depend on how the binary file was originally encoded, so having this information is crucial. Once imported, Audacity will convert the binary data into an audible waveform, which can be exported as a standard audio file like WAV or MP3.
For more advanced users or specific binary formats, SoX (Sound eXchange) is a powerful command-line tool that supports binary to audio conversion. SoX can handle raw audio files and offers precise control over the decoding process. To use SoX, open a terminal and input a command like `sox -t raw -r
Another approach involves using programming languages like Python with libraries such as NumPy and SciPy. This method is highly customizable and allows for fine-tuning the decoding process. Start by reading the binary file into a NumPy array using `numpy.fromfile()`. Then, normalize the data if necessary and use SciPy’s `scipy.io.wavfile.write()` to save the array as a WAV file. For example:
Python
Import numpy as np
From scipy.io.wavfile import write
Data = np.fromfile('input.bin', dtype=np.int16)
Write('output.wav', 44100, data)
This script assumes the binary file contains 16-bit signed integers at a sample rate of 44.1 kHz. Adjust the parameters based on your file’s specifications.
Lastly, online tools and converters provide a user-friendly alternative for those who prefer not to install software. Websites like Online Audio Converter or Binary to Sound allow you to upload binary files and specify decoding parameters through a web interface. While less flexible than software tools, these platforms are convenient for quick conversions without requiring technical expertise. However, ensure the website supports the specific binary format you’re working with, as compatibility can vary.
In summary, binary to audio conversion can be accomplished using a variety of software tools, each suited to different needs and skill levels. Whether you opt for Audacity, SoX, Python scripting, or online converters, understanding the binary file’s encoding parameters is key to successfully decoding it into audible sound. With the right tools and knowledge, transforming binary data into audio becomes an accessible and rewarding process.
Does Metal Block Out Sound? Exploring Its Acoustic Properties and Effectiveness
You may want to see also
Explore related products
![J-Tech Digital 8K HDMI Audio Extractor with eARC ARC 8K 60Hz 4K 120Hz, HDMI to Optical L/R Converter Adapter, HDCP 2.3 HDR CEC EDID [JTECH-8KAE]](https://m.media-amazon.com/images/I/61v+g5MyatL._AC_UY218_.jpg)
![J-Tech Digital 4K HDMI Audio Extractor, 4K@60Hz 1080P@120Hz 1080P@144Hz HDMI to Optical, 3.5mm Audio Converter Adapter, SPDIF, HDR10 CEC Digital Audio, DTS 5.1, [JTD18G-H5CHV2]](https://m.media-amazon.com/images/I/61NDtklpkPL._AC_UY218_.jpg)




![]()
Bit Rate and Sampling: Decode binary sound by analyzing bit rate and sampling frequency for accurate reconstruction
Decoding binary sound involves understanding and manipulating the fundamental parameters of digital audio: bit rate and sampling frequency. These parameters are crucial for accurately reconstructing the original analog sound wave from its binary representation. The bit rate, measured in kilobits per second (kbps), determines the amount of data used to represent the audio signal over time. A higher bit rate generally results in better sound quality because it captures more detail in the audio waveform. For example, a bit rate of 128 kbps is common for MP3 files, while higher-quality audio may use 320 kbps or more. When decoding binary sound, the bit rate directly influences the resolution of the audio, so it must be correctly identified and interpreted to avoid distortion or loss of fidelity.
Sampling frequency, measured in hertz (Hz), is another critical factor in decoding binary sound. It refers to the number of samples of the audio waveform taken per second during the analog-to-digital conversion process. The most common sampling rate for CD-quality audio is 44.1 kHz, meaning 44,100 samples are taken every second. To accurately reconstruct the sound, the decoder must use the correct sampling frequency to ensure the waveform is recreated without aliasing or other artifacts. If the sampling rate is too low, high-frequency components of the sound may be lost, while an incorrect rate during decoding can lead to pitch distortion or unintelligible audio.
Analyzing the bit rate and sampling frequency requires examining the audio file's metadata or header information, which often contains these parameters. For raw binary audio data, the bit rate and sampling frequency must be known or inferred from the context in which the data was generated. Once these values are determined, the decoder can process the binary data by mapping the bits to amplitude values at the specified sampling intervals. This step involves converting the binary representation into a sequence of numerical values that correspond to the original analog signal.
The relationship between bit rate and sampling frequency is essential for proper decoding. For instance, a higher bit rate allows for more precise quantization of each sample, reducing quantization noise. However, if the sampling frequency is inadequate, even a high bit rate cannot fully capture the original sound. Conversely, a high sampling frequency with a low bit rate may result in a detailed but noisy audio signal. Therefore, both parameters must be balanced and correctly applied during decoding to achieve accurate sound reconstruction.
In practice, decoding binary sound often involves using software tools or libraries that handle bit rate and sampling frequency automatically. However, understanding these parameters enables manual intervention when necessary, such as when dealing with corrupted files or non-standard formats. For example, if the sampling frequency is incorrectly stored in the file header, manually overriding it with the correct value can restore the audio to its intended quality. Similarly, adjusting the bit rate during decoding can help optimize the balance between file size and audio fidelity.
In summary, decoding binary sound hinges on accurately analyzing and applying the bit rate and sampling frequency. These parameters dictate the resolution and detail of the audio signal, and their correct interpretation is vital for faithful sound reconstruction. By understanding their roles and interdependencies, one can effectively decode binary audio data, ensuring the output matches the original analog waveform as closely as possible.
Sound Transit Costs: Breaking Down Fares, Fees, and Expenses
You may want to see also
Explore related products






![]()
Error Detection in Binary: Identify and correct errors in binary sound data to ensure clear audio output
Error detection in binary sound data is crucial for maintaining the integrity and clarity of audio output. Binary sound data, which represents audio as a sequence of 0s and 1s, is susceptible to errors during transmission, storage, or processing. These errors can manifest as noise, distortion, or missing segments in the audio. To address this, error detection techniques are employed to identify corrupted bits, ensuring that the decoded audio remains faithful to the original source. Common methods include parity checks, cyclic redundancy checks (CRC), and checksums, which analyze the binary data for inconsistencies. Once errors are detected, correction algorithms can be applied to restore the data to its original state, thereby preserving audio quality.
One effective approach to error detection in binary sound data is the use of parity bits. Parity involves adding an extra bit to each data unit (e.g., a byte) to indicate whether the number of 1s in that unit is even or odd. For example, in even parity, the added bit ensures the total count of 1s is even. If the parity bit does not match the expected value during decoding, an error is detected. While parity is simple to implement, it can only identify single-bit errors and is not suitable for correcting them. For audio applications, parity checks serve as a preliminary step to flag potential issues before more advanced correction techniques are applied.
Another powerful method for error detection is the Cyclic Redundancy Check (CRC). CRC generates a fixed-size checksum by treating the binary data as a polynomial and dividing it by a predetermined divisor. The remainder of this division is appended to the data. Upon decoding, the process is repeated, and if the new remainder does not match the original, an error is detected. CRC is highly effective at identifying burst errors, which are common in audio data due to interference or corruption. Its robustness makes it a preferred choice for ensuring the accuracy of binary sound data, especially in real-time applications where errors must be caught quickly.
Once errors are detected, error correction techniques such as Forward Error Correction (FEC) can be employed to restore the binary sound data. FEC works by adding redundant information to the original data, allowing the receiver to reconstruct the corrupted bits. For audio, Reed-Solomon coding is a popular FEC method, as it efficiently corrects multiple errors in a block of data. By applying FEC, even if some bits are lost or altered, the decoder can recover the original audio signal, minimizing distortion. This is particularly important in streaming or wireless audio transmission, where data loss is more likely to occur.
In practice, combining error detection and correction methods yields the best results for binary sound data. For instance, using CRC for detection followed by Reed-Solomon coding for correction ensures both accuracy and reliability. Additionally, interleaving can be applied to rearrange the data before transmission, spreading out errors so they are easier to correct. This is especially useful for audio, as it prevents consecutive errors from causing noticeable disruptions. By integrating these techniques, engineers can decode binary sound data with minimal errors, delivering clear and uninterrupted audio output to the listener.
Unveiling the Magic: How Project Bards Crafts Sound Creation
You may want to see also
Explore related products






![]()
Audio File Formats: Decode binary sound by understanding formats like WAV, MP3, and their binary structures
Decoding binary sound begins with understanding the underlying audio file formats and their binary structures. Audio files store sound data in specific formats, each with its own method of encoding and organizing binary information. Two of the most common formats are WAV (Waveform Audio File Format) and MP3 (MPEG-1 Audio Layer III). WAV files are uncompressed, meaning they retain all audio data in a raw, lossless format, while MP3 files use compression algorithms to reduce file size, often at the cost of some audio quality. To decode binary sound, you must first identify the file format and then interpret its binary structure.
WAV files are relatively straightforward to decode due to their simplicity. A WAV file consists of a header and the audio data itself. The header contains metadata, such as the file size, format type, and audio parameters (e.g., sample rate, bit depth, and number of channels). The audio data follows the header and is stored as raw, uncompressed samples. Each sample represents the amplitude of the sound wave at a specific point in time. To decode a WAV file, you read the header to understand the audio parameters, then interpret the binary data as a sequence of samples, converting them back into an analog signal using a digital-to-analog converter (DAC).
MP3 files, on the other hand, are more complex due to their compression algorithms. MP3 encoding uses techniques like psychoacoustic modeling and lossy compression to reduce file size. The binary structure of an MP3 file includes a frame header, side information, and compressed audio data. The frame header contains metadata about the frame, such as its size and bitrate, while the side information includes scaling factors and Huffman coding tables. The compressed audio data is encoded using techniques like MDCT (Modified Discrete Cosine Transform) and quantization. Decoding an MP3 file involves parsing the frame headers, applying inverse transforms, and reconstructing the audio signal.
Understanding the binary structure of these formats requires familiarity with their specifications. For WAV files, the RIFF (Resource Interchange File Format) structure is key, with chunks like `fmt ` (format) and `data` defining the audio parameters and raw samples, respectively. For MP3 files, the MPEG audio frame structure is critical, with each frame containing a sync word, version information, and audio data. Tools like hexadecimal editors or specialized software can help visualize and analyze these binary structures.
To decode binary sound effectively, start by examining the file’s header to identify its format. For WAV files, focus on extracting the audio samples from the `data` chunk. For MP3 files, parse the frame headers and apply the appropriate decompression algorithms. Libraries and SDKs like FFmpeg or Libav can simplify this process by providing pre-built functions for decoding various audio formats. By mastering the binary structures of formats like WAV and MP3, you gain the ability to decode, manipulate, and analyze audio data at a fundamental level.
Mastering Audio Mixing: Techniques to Bring Sounds Forward in Your Tracks
You may want to see also
Frequently asked questions
Binary sound refers to audio data represented in binary format (0s and 1s). It is typically encoded using methods like Pulse Code Modulation (PCM), where analog sound waves are sampled, quantized, and converted into binary values.
To decode binary sound, use audio software or programming libraries (e.g., Python’s `wave` or `pydub`) that can read binary data, interpret it as PCM or another format, and convert it into a playable audio file (e.g., WAV or MP3).
Tools like Audacity, MATLAB, or programming languages with audio libraries (Python, C++) can decode binary sound. Additionally, online converters or custom scripts can be used for specific binary-to-audio conversions.
Decoding binary sound manually is impractical due to its complexity and volume of data. Software or specialized tools are necessary to accurately interpret and convert binary data into audible sound.































