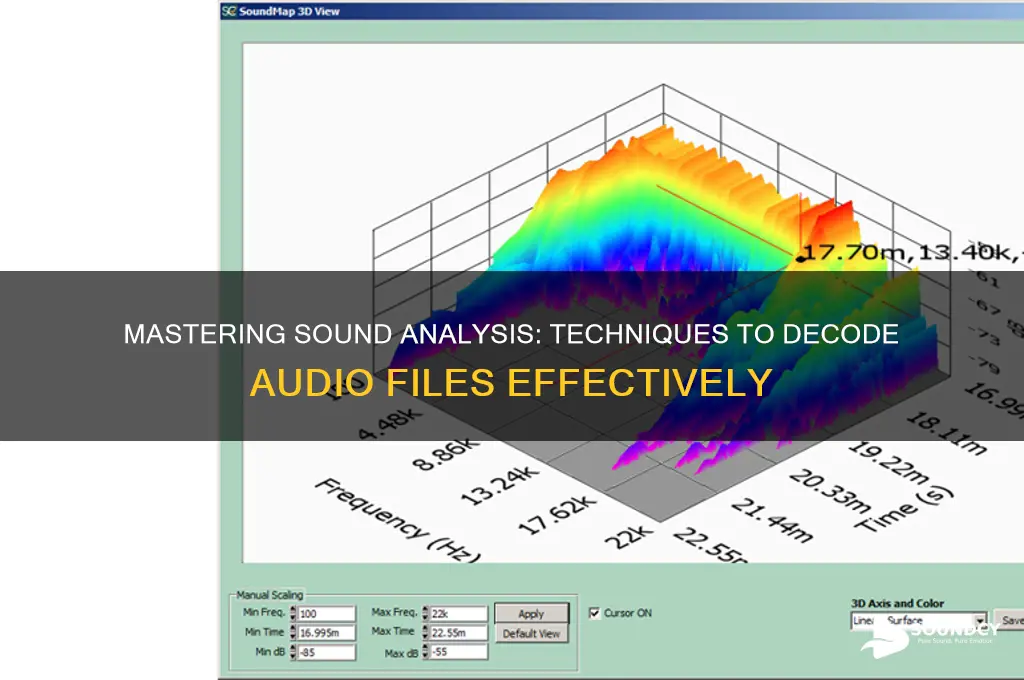
Analyzing a sound file involves a systematic process to extract meaningful information from audio data, whether for scientific research, music production, or forensic purposes. The first step typically includes importing the file into specialized software, such as Audacity, Adobe Audition, or MATLAB, which provides tools for visualization and manipulation. Key aspects of analysis include examining the waveform to understand amplitude variations, performing spectral analysis to identify frequency components, and applying techniques like Fourier Transform to break down the signal into its constituent frequencies. Additionally, features such as pitch, tempo, and noise levels can be quantified using algorithms or plugins. Advanced methods may involve machine learning models to classify sounds or detect patterns. Understanding the context of the audio—whether it’s speech, music, or environmental sounds—is crucial for selecting the appropriate analysis techniques and interpreting results accurately.
Explore related products






What You'll Learn
- Spectral Analysis: Examines frequency components over time using Fourier transforms to visualize sound characteristics
- Time-Domain Analysis: Studies waveform amplitude, duration, and patterns to understand sound structure and dynamics
- Pitch Detection: Identifies fundamental frequencies to determine pitch and tonal qualities in audio signals
- Noise Reduction: Techniques to remove unwanted background noise while preserving the original sound quality
- Feature Extraction: Extracts key attributes like MFCCs, chroma, or tempo for sound classification and processing
![]()
Spectral Analysis: Examines frequency components over time using Fourier transforms to visualize sound characteristics
Spectral analysis is a powerful technique used to examine the frequency components of a sound file over time, providing valuable insights into its characteristics. At its core, this method employs the Fourier Transform, a mathematical tool that decomposes a signal into its constituent frequencies. By applying the Fourier Transform to a sound file, analysts can convert the time-domain waveform into a frequency-domain representation, revealing the spectral content of the audio. This process is essential for understanding which frequencies are present, their amplitudes, and how they evolve throughout the recording.
To perform spectral analysis, the first step is to segment the sound file into short, overlapping windows. This is necessary because the Fourier Transform assumes the signal is stationary, which is rarely the case in real-world audio. Windowing functions, such as the Hann or Hamming window, are applied to minimize artifacts caused by abrupt signal truncation. Once the signal is windowed, the Fourier Transform is applied to each segment, generating a spectrogram—a visual representation of frequency over time. The spectrogram displays frequency on the y-axis, time on the x-axis, and amplitude as color intensity, allowing for detailed examination of the sound's spectral evolution.
The Fourier Transform can be implemented using either the Short-Time Fourier Transform (STFT) or the Discrete Fourier Transform (DFT), depending on the analysis requirements. The STFT is particularly useful for non-stationary signals, as it provides high temporal and frequency resolution by analyzing short segments of the signal. In contrast, the DFT is applied to the entire signal, offering a global view of the frequency content but with limited time resolution. Tools like MATLAB, Python libraries (e.g., Librosa, SciPy), or specialized software (e.g., Audacity, Adobe Audition) can facilitate these computations and visualize the results.
Interpreting the results of spectral analysis involves identifying key features such as dominant frequencies, harmonics, and transient events. For example, in speech analysis, formants (concentrations of acoustic energy) can be observed as horizontal bands in the spectrogram, while in music, harmonics appear as evenly spaced frequency peaks. Spectral analysis also aids in noise reduction, as unwanted frequencies can be isolated and filtered out. Additionally, it is instrumental in applications like audio fingerprinting, instrument identification, and sound quality assessment.
In summary, spectral analysis using Fourier transforms is a cornerstone of sound file analysis, offering a detailed view of frequency components over time. By converting time-domain signals into frequency-domain representations, analysts can visualize and interpret complex audio characteristics. Whether for scientific research, audio engineering, or creative applications, mastering spectral analysis techniques empowers users to extract meaningful information from sound files and manipulate them effectively.
Unveiling the Magic: How Electric Guitars Create Their Iconic Sound
You may want to see also
Explore related products






![]()
Time-Domain Analysis: Studies waveform amplitude, duration, and patterns to understand sound structure and dynamics
Time-domain analysis is a fundamental technique in sound file analysis that involves examining the waveform directly over time. This method focuses on the amplitude, duration, and patterns of the waveform to gain insights into the sound’s structure and dynamics. By visualizing the sound as a waveform, analysts can observe how the signal changes moment by moment, revealing essential characteristics such as loudness variations, silence intervals, and overall shape. Tools like digital audio workstations (DAWs) or software like Audacity provide waveform displays, enabling users to zoom in and out to study both macro and micro details of the audio signal.
One key aspect of time-domain analysis is studying the amplitude of the waveform, which directly corresponds to the sound’s loudness. Peaks in the waveform indicate high-amplitude regions, representing louder sections of the audio, while lower regions signify softer passages. Analyzing amplitude over time helps identify dynamic changes, such as crescendos, decrescendos, or sudden spikes, which are crucial for understanding the emotional and structural flow of the sound. Additionally, amplitude analysis can reveal clipping—instances where the waveform exceeds the maximum allowable level—which may indicate distortion or recording issues.
Duration analysis in the time domain involves measuring the length of specific events or segments within the sound file. This includes identifying the start and end points of individual sounds, such as notes in music or syllables in speech, and calculating their respective durations. By segmenting the waveform, analysts can determine the timing of events, which is vital for tasks like beat detection, rhythm analysis, or aligning audio with other media. Duration analysis also aids in detecting anomalies, such as unusually long silences or abrupt cuts, which may require editing or further investigation.
Patterns within the waveform are another critical focus of time-domain analysis. Recurring shapes or structures in the waveform can indicate periodicity, which is often associated with pitched sounds or rhythmic elements. For example, a consistent, repeating pattern may suggest a steady tone or a drumbeat, while irregular patterns could represent noise or complex timbres. Analyzing these patterns helps in characterizing the sound’s nature, whether it is musical, speech-based, or environmental. Pattern recognition also assists in identifying artifacts, such as background interference or glitches, which can degrade audio quality.
Finally, time-domain analysis provides a foundation for understanding the overall dynamics of a sound file. Dynamics refer to how the sound evolves over time, encompassing elements like attack, decay, sustain, and release in individual sounds or the ebb and flow of an entire audio track. By closely examining the waveform, analysts can map out these dynamic changes, which are essential for tasks like audio mixing, mastering, or sound design. For instance, a sharp attack followed by a gradual decay might characterize a percussion instrument, while a sustained, steady waveform could represent a long vocal note. This detailed understanding of dynamics allows for informed decision-making in audio editing and enhancement.
Do Quartz Oscillators Produce Sound? Unveiling the Truth Behind the Buzz
You may want to see also
Explore related products






![]()
Pitch Detection: Identifies fundamental frequencies to determine pitch and tonal qualities in audio signals
Pitch detection is a fundamental aspect of sound file analysis, focusing on identifying the fundamental frequencies (F0) that define the pitch and tonal qualities of an audio signal. The process begins with understanding that pitch is the perceptual property of sound that allows us to distinguish between "high" and "low" tones, directly related to the frequency of the sound waves. To analyze pitch, the first step involves extracting the fundamental frequency from the audio signal, which is typically the lowest frequency in a harmonic series and the most perceptually dominant component of a sound. Techniques such as the Short-Time Fourier Transform (STFT) or autocorrelation are commonly employed to estimate F0. STFT provides a time-frequency representation of the signal, allowing for the identification of dominant frequencies over short time intervals, while autocorrelation measures the similarity of a signal with a delayed version of itself, highlighting periodicities that correspond to the fundamental frequency.
Once the fundamental frequency is estimated, the next step is to refine and validate the pitch detection. This often involves addressing challenges such as noise, harmonics, and variations in signal amplitude. Advanced algorithms like the Yin algorithm or the harmonic product spectrum (HPS) can improve accuracy by focusing on the periodicity of the signal and reducing the impact of noise. The Yin algorithm, for instance, compares the signal with shifted versions of itself to find the best periodicity, while HPS enhances the detection of harmonic structures by multiplying spectral peaks. These methods ensure that the detected pitch is robust and reliable, even in complex audio environments.
After detecting the fundamental frequency, the analysis proceeds to determine the tonal qualities of the audio signal. Tonal qualities refer to characteristics such as timbre, which is influenced by the presence and relative amplitudes of harmonics. By examining the harmonic series—the integer multiples of the fundamental frequency—analysts can infer the richness and color of the sound. For example, a pure sine wave has no harmonics and sounds "tonal" in a simplistic way, whereas a musical instrument's sound contains multiple harmonics that contribute to its unique timbre. Spectral analysis tools, such as spectrograms, are invaluable for visualizing these harmonic structures and understanding how they evolve over time.
Practical applications of pitch detection in sound file analysis are diverse, ranging from music transcription and speech processing to audio restoration and instrument tuning. In music, pitch detection enables automatic transcription of melodies and harmonies, facilitating tasks like MIDI conversion or score generation. In speech analysis, it helps in identifying phonemes and prosody, which are critical for speech recognition systems and voice analysis. Additionally, pitch detection is essential in audio restoration, where it can isolate and correct pitch-related distortions or artifacts. For musicians and sound engineers, tools that accurately detect pitch are indispensable for tuning instruments, analyzing performances, and ensuring high-quality audio production.
To implement pitch detection effectively, it is crucial to select the appropriate tools and software. Many digital audio workstations (DAWs) and specialized software packages, such as Audacity, MATLAB, or Python libraries like Librosa and PyDub, offer built-in or customizable pitch detection functionalities. These tools often provide graphical interfaces or scripting capabilities, allowing users to tailor the analysis to their specific needs. When working with these tools, it is important to consider factors like sampling rate, window size, and threshold settings, as they significantly impact the accuracy of pitch detection. Experimenting with different parameters and comparing results can help optimize the analysis for the specific characteristics of the audio file.
In conclusion, pitch detection is a critical technique in sound file analysis, enabling the identification of fundamental frequencies and the determination of pitch and tonal qualities. By leveraging methods like STFT, autocorrelation, and advanced algorithms, analysts can extract precise pitch information even from complex audio signals. Understanding the harmonic series and tonal qualities further enriches the analysis, providing insights into the sound's timbre and structure. With the right tools and techniques, pitch detection becomes a powerful asset in various applications, from music and speech processing to audio restoration and beyond. Mastery of this technique empowers users to explore and manipulate audio signals with greater depth and precision.
Unveiling the Tuba's Magic: How Air and Brass Create Deep Sounds
You may want to see also
Explore related products






![]()
Noise Reduction: Techniques to remove unwanted background noise while preserving the original sound quality
Noise reduction is a critical process in sound file analysis, aiming to remove unwanted background noise while preserving the integrity and quality of the original audio. One of the most effective techniques is spectral subtraction, which involves identifying and isolating noise in the frequency domain. This method works by estimating the noise profile during silent intervals or known noise-only segments and then subtracting this profile from the entire audio signal. Advanced algorithms, such as the Wiener filter, refine this process by minimizing the impact on the desired signal, ensuring that only noise is removed. Tools like Audacity and Adobe Audition provide user-friendly interfaces for applying spectral subtraction, making it accessible for both beginners and professionals.
Another powerful technique is adaptive noise reduction, which dynamically adjusts to changes in noise levels over time. This method uses real-time analysis to continuously update the noise profile, making it particularly effective for recordings with varying background noise, such as outdoor interviews or live performances. Adaptive filters, like the Least Mean Squares (LMS) algorithm, are commonly employed to achieve this. By focusing on the temporal characteristics of the noise, adaptive noise reduction ensures that transient sounds or sudden noise spikes are effectively mitigated without affecting the primary audio content.
For more complex scenarios, machine learning-based noise reduction has emerged as a cutting-edge solution. Deep learning models, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs), are trained on large datasets of noisy and clean audio pairs to learn patterns and distinguish between noise and desired signals. These models can handle a wide range of noise types, including non-stationary noise, and often outperform traditional methods in terms of accuracy and sound quality preservation. Tools like iZotope RX and Krisp leverage machine learning to deliver professional-grade noise reduction for audio and video applications.
A simpler yet effective approach is low-pass, high-pass, or band-stop filtering, which targets specific frequency ranges where noise is prominent. For instance, a high-pass filter can remove low-frequency hums, while a band-stop filter can eliminate narrowband interference like electrical buzzing. However, this method requires careful application to avoid cutting out desirable frequencies in the original audio. It is best suited for cases where the noise has a distinct frequency signature that does not overlap with the primary signal.
Lastly, phase-based noise reduction techniques focus on the phase differences between the noise and the desired signal. Since noise is often uncorrelated with the primary audio, phase manipulation can help isolate and suppress it. This method is particularly useful in stereo recordings, where phase relationships between channels can be exploited to reduce noise. While more specialized, phase-based techniques can achieve excellent results when combined with other noise reduction methods, ensuring a cleaner and more natural-sounding output.
In conclusion, noise reduction in sound file analysis requires a combination of techniques tailored to the specific characteristics of the noise and the audio content. By leveraging spectral subtraction, adaptive filtering, machine learning, frequency filtering, and phase manipulation, it is possible to effectively remove unwanted background noise while preserving the original sound quality. Each method has its strengths and limitations, and the choice of technique depends on the complexity of the noise and the desired outcome. Proper application of these tools ensures that the final audio remains clear, professional, and true to its original intent.
Does a Falling Tree Make a Sound? Exploring the Science and Philosophy
You may want to see also
Explore related products


$121.1 $142.5



![]()
Feature Extraction: Extracts key attributes like MFCCs, chroma, or tempo for sound classification and processing
Feature extraction is a critical step in sound file analysis, as it transforms raw audio data into a more manageable and meaningful representation for classification and processing tasks. This process involves identifying and isolating key attributes that capture the essence of the sound, making it easier for machine learning algorithms or other analytical tools to interpret. Among the most widely used features are Mel-Frequency Cepstral Coefficients (MFCCs), chroma, and tempo, each offering unique insights into the audio signal. By extracting these features, analysts can focus on the most relevant aspects of the sound, reducing dimensionality and improving computational efficiency.
MFCCs are a cornerstone of audio feature extraction, particularly in speech and music recognition systems. They are derived by mapping the audio spectrum onto the Mel scale, which aligns more closely with human auditory perception. The process begins with framing the audio signal into short, overlapping windows, followed by applying the Fourier Transform to compute the power spectrum. These spectra are then filtered using triangular Mel-scale filters, and a logarithmic transformation is applied to mimic the human ear's non-linear response to sound intensity. Finally, a discrete cosine transform (DCT) is used to decorrelate the filter bank outputs, yielding the MFCCs. These coefficients effectively capture the spectral envelope of the sound, making them robust to variations in loudness and noise.
Chroma features, on the other hand, are particularly useful for music analysis, as they capture harmonic and melodic characteristics. Chroma represents the distribution of energy across different pitch classes (e.g., C, C#, D, etc.) over time, providing a time-frequency representation that is invariant to octave changes. This is achieved by summing the spectral energy within each semitone bin, typically using a 12-bin chroma vector to correspond to the Western musical scale. Chroma features are especially valuable for tasks like genre classification, chord recognition, and music structure analysis, as they highlight the tonal content of the audio signal.
Tempo extraction is another essential feature, particularly for rhythm-based analysis in music. Tempo refers to the speed or pace of a musical piece, often measured in beats per minute (BPM). Extracting tempo involves detecting recurring patterns in the audio signal, such as beat onsets or periodicities. Common techniques include using onset detection algorithms, which identify sudden energy increases in the signal, or autocorrelation methods, which measure the similarity of the signal with a delayed copy of itself. Tempo features are crucial for applications like music synchronization, danceability prediction, and rhythm-based music recommendation systems.
In practice, feature extraction often combines multiple attributes like MFCCs, chroma, and tempo to create a comprehensive feature set. This multi-faceted approach ensures that both spectral and temporal characteristics of the sound are captured, enhancing the accuracy of downstream tasks such as classification, clustering, or retrieval. Libraries and frameworks like Librosa, Essentia, and PyTorch Audio provide pre-built functions for extracting these features, simplifying the implementation process for developers and researchers. By leveraging these tools and understanding the underlying principles, analysts can effectively transform raw audio data into actionable insights for a wide range of applications.
Does Macintosh Have Sound? Exploring Audio Capabilities of Mac Devices
You may want to see also
Frequently asked questions
Popular software for sound file analysis includes Audacity (free and open-source), Adobe Audition, MATLAB with audio processing toolboxes, and specialized tools like Praat for speech analysis.
Use a spectrogram or frequency spectrum analysis. Most audio software provides these tools, which display frequency over time or as a static plot.
Waveform analysis shows the amplitude of the sound over time, while spectral analysis (e.g., FFT) breaks the sound into its frequency components, revealing pitch and harmonics.
Yes, use feature extraction techniques. Tools like Librosa (Python library), Praat, or MATLAB can extract pitch, tempo, MFCCs (Mel-Frequency Cepstral Coefficients), and more.
Analyze the frequency spectrum for unexpected peaks or use noise reduction tools. Visual inspection of the spectrogram or waveform can also highlight anomalies.




























