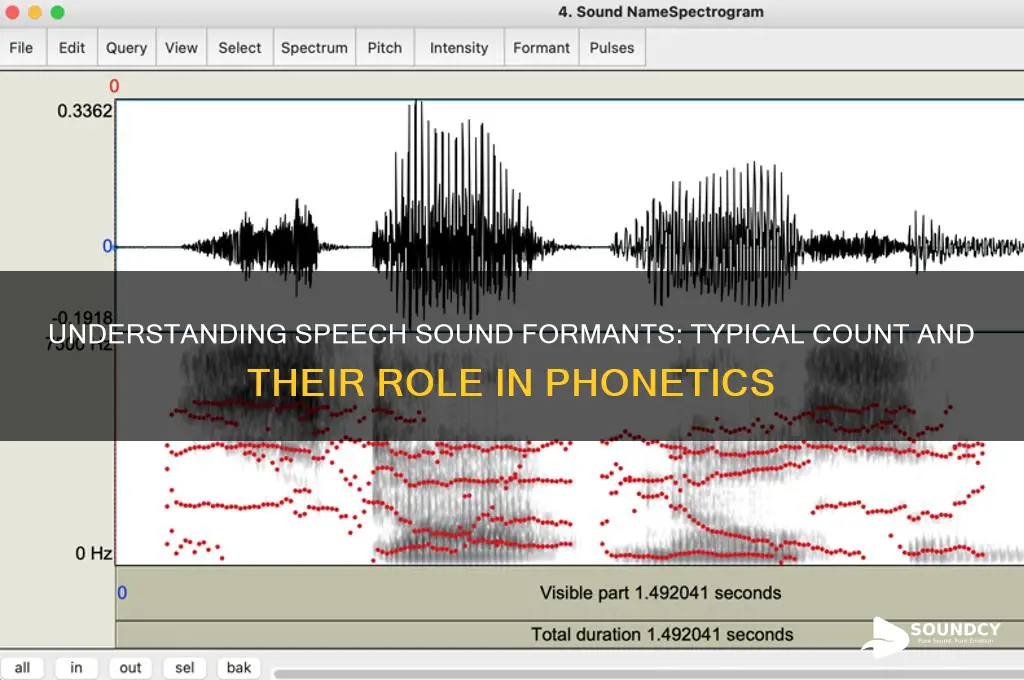
The number of formants in a speech sound is a fundamental aspect of phonetics, as formants are the resonant frequencies that characterize the vowel and consonant qualities of speech. Typically, a speech sound has three to five formants, with the first three (F1, F2, and F3) being the most significant in distinguishing vowel identities. The first formant (F1) is primarily associated with the openness of the vowel, the second formant (F2) with the frontness or backness, and the third formant (F3) with the rounding of the lips. While higher formants (F4 and F5) exist, they contribute less to perceptual differences and are often influenced by individual vocal tract characteristics or specific articulatory contexts. Understanding the number and role of formants is crucial for analyzing speech production, perception, and synthesis.
| Characteristics | Values |
|---|---|
| Number of Formants in Speech Sounds | Typically 4-5 |
| Frequency Range of Formants | F1: 200-1000 Hz, F2: 1000-2500 Hz, F3: 2500-3500 Hz, F4: 3500-5000 Hz, F5: >5000 Hz |
| Role of Formants | Determine vowel quality and distinctiveness |
| Influence of Vocal Tract Shape | Formant frequencies are shaped by vocal tract configuration |
| Speaker Variability | Formant frequencies vary by age, gender, and anatomy |
| Importance in Speech Perception | Critical for human listeners to distinguish between speech sounds |
| Use in Speech Synthesis | Formants are modeled to generate natural-sounding speech |
| Formant Transitions | Important for consonant identification and naturalness |
| Formant Tuning | Slight adjustments occur based on linguistic context |
| Cross-Language Differences | Formant patterns vary across languages but typically follow the 4-5 formant structure |
Explore related products






What You'll Learn
- Formant Definition: Frequency bands in speech spectrum, crucial for vowel and consonant identification
- Typical Formant Count: Most speech sounds have 4-5 formants, depending on articulation
- Formant Role in Vowels: First two formants primarily distinguish vowels in acoustic analysis
- Formant Role in Consonants: Formants help differentiate place and manner of consonant articulation
- Variability Factors: Speaker, age, gender, and language influence formant number and frequency
![]()
Formant Definition: Frequency bands in speech spectrum, crucial for vowel and consonant identification
Speech sounds are not just random noise; they are structured acoustic events characterized by specific frequency bands called formants. These formants are the resonances of the vocal tract, amplified by its shape and length, which give each vowel and consonant its unique identity. Typically, a speech sound has three to five formants, though the first four are most critical for perception. The first formant (F1) is associated with the openness of the vowel, while the second (F2) relates to the frontness or backness. Higher formants (F3 and F4) contribute to finer distinctions, such as rounding or tension in the articulators. Understanding these frequency bands is essential for fields like phonetics, speech synthesis, and hearing aid technology, where precise identification of speech sounds is paramount.
Consider the vowel /i/ as in "see" and /u/ as in "shoe." Despite both being high vowels, their distinctiveness lies in the positioning of F1 and F2. For /i/, F1 is relatively high, and F2 is also high, reflecting the tongue’s front and high position. In contrast, /u/ has a high F1 but a low F2, indicating a back and high tongue position. This example illustrates how formants act as acoustic fingerprints, allowing listeners to differentiate between sounds effortlessly. Without these frequency bands, speech would be a muddled, indistinguishable stream of noise.
To analyze formants, speech scientists use spectrograms, visual tools that display the frequency spectrum over time. By examining the peaks in these spectrograms, researchers can pinpoint the formant frequencies and their movements during articulation. For instance, during the transition from /a/ to /i/, F1 rises sharply, while F2 shifts from low to high. This dynamic interplay of formants is crucial for understanding not only static vowels but also diphthongs and consonant-vowel coarticulation. Practical applications include speech therapy, where clinicians use formant analysis to diagnose articulation disorders, and forensic phonetics, where formant patterns help identify speakers.
While formants are indispensable for speech perception, they are not the sole determinants of sound identity. Factors like voice quality, pitch, and noise components also play roles. For instance, a whisper lacks the fundamental frequency of voiced speech but retains formant structure, allowing listeners to recognize vowels. Similarly, consonants rely on formants but also on turbulence and closure characteristics. Thus, formants are a cornerstone of speech acoustics, but they operate within a complex interplay of other acoustic features.
In summary, formants are the frequency bands in the speech spectrum that serve as the backbone of vowel and consonant identification. Typically numbering three to five, the first four formants are most critical for distinguishing sounds. Their analysis through tools like spectrograms provides insights into articulation and coarticulation, with practical applications across multiple disciplines. While not the only factor in speech perception, formants are undeniably central to how we decode the acoustic world of language.
Exploring Rhythm's Pulse: Unveiling the Sonic Signature of Musical Patterns
You may want to see also
Explore related products






![]()
Typical Formant Count: Most speech sounds have 4-5 formants, depending on articulation
Speech sounds are not just random vibrations; they are structured acoustic events characterized by specific frequency bands called formants. Typically, most speech sounds exhibit 4 to 5 formants, though this number can vary based on the articulation of the sound. These formants are the resonant frequencies of the vocal tract, which amplify certain frequencies and give each speech sound its unique spectral signature. For instance, the vowel /i/ (as in "see") has a higher first formant (F1) and a lower second formant (F2) compared to the vowel /u/ (as in "do"), illustrating how formant frequencies differentiate sounds.
The number of formants is directly tied to the complexity of the vocal tract’s shape during articulation. When producing a vowel, the tongue, lips, and jaw adjust the tract’s dimensions, creating regions of resonance. While the first three formants (F1, F2, F3) are most critical for vowel identification, higher formants (F4, F5) contribute to the richness and naturalness of the sound. Consonants, on the other hand, often have fewer prominent formants due to partial obstruction of the vocal tract, but they still exhibit formant structures that aid in their perception.
Articulation plays a pivotal role in determining the formant count. For example, a high front vowel like /i/ may show a clear F4, while a low back vowel like /ɑ/ (as in "father") might not. Similarly, nasal sounds introduce additional formants due to the resonance in the nasal cavity. Speech pathologists and linguists often analyze these formants to diagnose articulation disorders or study phonetic variations across languages. Tools like spectrograms are used to visualize these formants, providing a detailed acoustic profile of speech sounds.
Understanding the typical formant count is essential for applications like speech synthesis and recognition. In text-to-speech systems, accurately modeling 4-5 formants ensures natural-sounding speech, while in speech recognition, identifying these formants helps distinguish between similar sounds. For instance, misidentifying F2 and F3 can lead to confusion between /e/ (as in "bed") and /ɛ/ (as in "bet"). Practical tips for researchers include focusing on the first three formants for vowel classification and considering higher formants for fine-tuning speech models.
In summary, the typical formant count of 4-5 in speech sounds is a fundamental acoustic principle shaped by articulation. This knowledge is not only crucial for theoretical linguistics but also has practical implications in technology and speech therapy. By analyzing formants, we gain deeper insights into the mechanics of human speech and improve tools that rely on accurate speech representation. Whether studying vowels, consonants, or nasal sounds, the formant count remains a key metric for understanding and replicating speech.
Proving Sound Mind: Essential Steps for Legal and Personal Validation
You may want to see also
Explore related products






![]()
Formant Role in Vowels: First two formants primarily distinguish vowels in acoustic analysis
Speech sounds, particularly vowels, are characterized by their formant structure, which consists of distinct frequency bands where sound energy is concentrated. Typically, a speech sound has three to five formants, though the first three are most prominent and functionally significant. However, in the context of vowel distinction, the first two formants (F1 and F2) play a disproportionately critical role. These formants correspond to the tongue’s vertical and horizontal positions during articulation, respectively. For instance, the vowel /i/ (as in "see") has a high F1 and low F2, while /u/ (as in "shoe") has a high F1 and high F2. This pattern allows acoustic analysts to map vowels in a formant chart, where F1 values are plotted on the vertical axis and F2 on the horizontal axis, creating a visual representation of vowel spaces.
To understand the practical application of this principle, consider the following analytical approach: when analyzing vowel production, researchers measure formant frequencies using spectrographic tools. For adult English speakers, F1 typically ranges between 200–1000 Hz, while F2 falls between 800–2500 Hz. By focusing on these ranges, linguists can differentiate between vowels like /æ/ (as in "cat") and /ɪ/ (as in "sit"), which differ primarily in their F1 values. This method is particularly useful in speech pathology, where deviations in formant frequencies can indicate articulation disorders. For example, a child with a lisp may exhibit elevated F2 values for front vowels, signaling improper tongue placement.
From a persuasive standpoint, the reliance on F1 and F2 in vowel analysis underscores their efficiency as diagnostic tools. While higher formants (F3 and beyond) contribute to the timbre and individuality of speech, they are less consistent across speakers and less critical for vowel identification. This makes F1 and F2 ideal for cross-linguistic studies, speech synthesis, and automatic speech recognition systems. For instance, text-to-speech technologies prioritize these formants to generate natural-sounding vowels, ensuring clarity and intelligibility. By focusing on the first two formants, developers can create more accurate and resource-efficient models, even when working with limited data.
A comparative analysis further highlights the unique role of F1 and F2. Unlike consonants, which rely heavily on higher formants and spectral transitions, vowels are primarily defined by their steady-state formant structure. For example, the contrast between /e/ (as in "bed") and /ɛ/ (as in "bet") in English is almost entirely captured by differences in F1, with minimal contribution from F2 or higher formants. This simplicity makes vowels more predictable in acoustic terms, facilitating their use in language learning and speech therapy. For instance, ESL learners can be trained to manipulate F1 and F2 to improve their pronunciation of English vowels, focusing on specific frequency targets for each sound.
In conclusion, the first two formants serve as the cornerstone of vowel distinction in acoustic analysis, offering a reliable and efficient framework for understanding speech production. Their direct correlation with articulatory movements and their consistency across speakers make them indispensable tools in linguistics, technology, and clinical practice. By mastering the role of F1 and F2, practitioners can enhance speech analysis, improve communication technologies, and address speech disorders more effectively. This focused approach not only simplifies complex acoustic data but also bridges the gap between theory and practical application, making it a vital concept in the study of speech sounds.
Exploring the Mississippi Sound: Location, Ecology, and Coastal Charm
You may want to see also
Explore related products






![]()
Formant Role in Consonants: Formants help differentiate place and manner of consonant articulation
Speech sounds, particularly consonants, rely heavily on formants to convey distinctiveness in articulation. Typically, vowels are associated with the first three to five formants (F1-F5), but consonants, though less formant-dependent, utilize these acoustic resonances to differentiate place and manner of articulation. For instance, the velar stop /k/ and the palatal fricative /ʃ/ exhibit unique formant patterns that help listeners distinguish between them. This subtle interplay of formants ensures clarity in speech, even in noisy environments.
To understand how formants achieve this, consider the role of the vocal tract’s shape during consonant production. The place of articulation—whether bilabial, alveolar, or velar—alters the tract’s geometry, thereby shifting formant frequencies. For example, the bilabial /p/ produces a distinct formant structure compared to the alveolar /t/, despite both being stops. Similarly, the manner of articulation, such as whether a sound is a stop, fricative, or nasal, further modulates formant characteristics. Fricatives like /s/ and /f/ introduce turbulence, creating unique formant patterns that contrast with the more stable resonances of stops.
Practical analysis of formants in consonants often involves spectrographic examination. Linguists and speech scientists use tools like Praat to visualize formant frequencies and bandwidths, identifying how these parameters vary across consonants. For instance, nasals like /m/ and /n/ exhibit lowered F2 and F3 due to velar lowering, distinguishing them from oral stops. This methodical approach not only aids in phonetic transcription but also informs speech therapy and language learning, where precise articulation is critical.
A comparative perspective highlights the efficiency of formants in consonant differentiation. While fundamental frequency (F0) primarily encodes pitch, formants provide finer-grained details about articulation. For example, the contrast between /s/ and /ʃ/ is more evident in their formant structures than in their F0. This specificity is particularly useful in tonal languages, where pitch variations might otherwise obscure consonant distinctions. By focusing on formants, listeners can disentangle overlapping acoustic cues, enhancing speech intelligibility.
Incorporating formant analysis into speech training yields practical benefits. For learners of a second language, understanding formant patterns can improve pronunciation accuracy. For instance, English learners often struggle with the distinction between /θ/ and /s/; visualizing formant differences can provide a tangible target for practice. Similarly, speech therapists use formant feedback to help clients with articulation disorders, such as substituting /r/ with /w/, by highlighting the formant discrepancies between these sounds. This targeted approach transforms abstract phonetic concepts into actionable guidance.
Understanding Sound Transmission: How Waves Travel Through Mediums
You may want to see also
Explore related products






![]()
Variability Factors: Speaker, age, gender, and language influence formant number and frequency
Speech sounds are not one-size-fits-all; their acoustic fingerprints, known as formants, vary significantly across individuals. A typical speech sound has four to five formants, but this is just a starting point. The number and frequency of these formants are not static—they are shaped by a complex interplay of factors, including the speaker’s identity, age, gender, and language. Understanding these variability factors is crucial for fields like speech recognition, linguistics, and even forensic phonetics, where subtle differences in formants can reveal much about the speaker.
Consider the speaker-specific influence on formant frequencies. Each person’s vocal tract anatomy—length, width, and shape—is unique, much like a fingerprint. For instance, taller individuals often have longer vocal tracts, which lower formant frequencies, giving their speech a deeper resonance. Conversely, shorter individuals tend to have higher formant frequencies. This variability is why voice recognition systems must account for speaker-specific traits to accurately identify individuals. Practical tip: When training speech models, include diverse speakers to capture this anatomical range and improve accuracy.
Age plays a significant role in formant variability, particularly during developmental stages. Children’s vocal tracts are smaller, resulting in higher formant frequencies compared to adults. For example, the first formant (F1) of the vowel /a/ in a 5-year-old can be around 800 Hz, while in an adult, it drops to approximately 500–700 Hz. As individuals age, vocal tract tissues may lose elasticity, further altering formant frequencies. Caution: In speech therapy or language research involving children, age-specific formant norms must be applied to avoid misdiagnosis or misinterpretation.
Gender is another critical factor, with biological differences in vocal tract dimensions leading to distinct formant patterns. On average, males have longer vocal tracts than females, resulting in lower formant frequencies. For instance, the first formant of the vowel /i/ in adult males typically ranges from 250–300 Hz, while in females, it is around 350–450 Hz. However, these differences are not absolute; factors like hormone levels, voice training, and even cultural speech patterns can influence formant frequencies. Takeaway: When analyzing speech data, always consider gender as a variable to avoid biased conclusions.
Finally, language introduces another layer of complexity. Different languages use distinct vowel and consonant systems, which affect formant frequencies. For example, English has a relatively small vowel inventory compared to languages like Swedish or Mandarin, leading to differences in formant spacing. Additionally, tonal languages like Thai or Cantonese may exhibit unique formant patterns due to pitch variations. Comparative analysis: A study comparing English and Mandarin speakers found that Mandarin speakers had higher F1 frequencies for certain vowels due to tonal requirements. Practical tip: When working with multilingual datasets, normalize formant measurements based on language-specific norms to ensure accurate comparisons.
In summary, the number and frequency of formants in speech sounds are far from uniform. Speaker anatomy, age, gender, and language all contribute to this variability, making it essential to approach formant analysis with a nuanced understanding of these factors. By accounting for these influences, researchers and practitioners can unlock deeper insights into the rich tapestry of human speech.
Panasonic UB9000: Dolby Atmos Sound Format Compatibility Explained
You may want to see also
Frequently asked questions
A speech sound typically has 3 to 5 formants, depending on the vowel or consonant and the speaker's vocal tract characteristics.
No, the number of formants varies depending on the speech sound. Vowels generally have more prominent and distinct formants (usually 3-5), while consonants may have fewer or less defined formants.
Vowels have more formants because they are produced with an open vocal tract, allowing for resonant frequencies to be more clearly defined. Consonants, especially obstruents, involve constrictions that reduce the number of prominent formants.
Yes, the number and frequency of formants can vary based on the speaker's anatomy, age, gender, and the specific language or dialect being spoken. These factors influence the shape and size of the vocal tract.































